tornado recipe
for me
1,tornado是一个单进程http server(当然也支持wsgi)
所以不需要web server来处理http协议,web server直接作为proxy转发即可。
一般根据服务器的core数目来决定启动几个tornado进程(bind在不同的端口上)。
httpserver.py中的_on_headers(),硬编码来处理http请求(http协议的科普备忘看这里:http://roclinux.cn/?p=3450)。
2,异步io
对外展现往往是callback模式,内部实现用io复用机制来进行event通知。
@tornado.web.asynchronous时不立即进行http应答,从而达到long polling效果。
管理大量慢连接,利用了epoll,这里有一篇对epoll event的注解:
http://hi.baidu.com/soulshape/item/0c7e00c0866e207488ad9ee5
特别留意EPOLLRDHUP。
python示例:http://scotdoyle.com/python-epoll-howto.html
其中example4展示了ET模式下的注意点:
a,w/r直到全部结束为止,否则下次无法感知;
b,留意w时可以通过buf避免sock_write堵塞:http://www.cnblogs.com/OnlyXP/archive/2007/08/10/851222.html
不过检查了一下tornado和redis,用的都是LT模式。
3,chat demo
观察者模式,多个requery注册进来,重点是全局list中握着的是多个连接上的回调函数,所以就不用关心底层的sock了。
留意同一个类的不同对象的方法是可区分的:method bound on instance
>>> a.func <bound method A.func of <__main__.A instance at 0xb751c7cc>> >>> b.func <bound method A.func of <__main__.A instance at 0xb751c88c>> >>> id(a.func) 3075798876L >>> id(b.func) 3075798876L >>> a.func == b.func False >>> hash(a.func) 3389 >>> hash(b.func) 3529
顺便再科普一下set:The elements of a set must be hashable。
4,tornado.gen
避免逻辑被各种onXXX callback切割的支离破碎。
from tornado.platform.caresresolver import CaresResolver
from tornado import gen
import tornado.ioloop
@gen.coroutine
def resolver():
resolver = CaresResolver()
result = yield resolver.resolve('baidu.com',80) //不会阻塞住进程,其他event可以得到响应。
print(result)
tornado.ioloop.IOLoop.instance().stop()
resolver()
tornado.ioloop.IOLoop.instance().start()
不过不是很好理解。。。也可以老老实实用callback。
one loop per core 并发模型
一,缘起:
简单易开发的同步服务模型:sock句柄池+threadpool。
满足大部分需求(特别是计算型需求),qps<1000,也基本够用。
二,问题:
线程逻辑I/O化,需要处理大并发+[慢]连接,力不从心。
机器cpu idle尚高,明显有提升的余地。
三,解决方案:
one loop per core
异步模型,程序逻辑(尽量也为异步,不能长时间堵塞)勾在event回调中,状态机式编写逻辑。
核心是各个os提供的event api(如epoll),避免了busy loop。
decorator in python
依然是在stackoverflow中找到了一个非常详尽的解释,见这里。
要点归纳如下:
1,等价语义
def makeitalic(fn):
def wrapped(str):
return "<i>" + fn(str) + "</i>"
return wrapped
@makeitalic
def hello(str):
return "hello "+str
#等价于hello = makeitalic(hello)
print hello("world")
#output:<i>hello world</i>
2,基础:函数是对象,所以可以任意赋值;函数可以在另一个函数中定义。=> a function can return another function。
3,关键,为啥要用它呢?
美观&非侵入式的增强函数的行为。
4,来自的同篇帖子的一个实例(配合上*args,**kwargs可以接受任意参数):
def benchmark(func):
"""
A decorator that prints the time a function takes
to execute.
"""
import time
def wrapper(*args, **kwargs):
t = time.clock()
res = func(*args, **kwargs)
print func.__name__, time.clock()-t
return res
return wrapper
def logging(func):
"""
A decorator that logs the activity of the script.
(it actually just prints it, but it could be logging!)
"""
def wrapper(*args, **kwargs):
res = func(*args, **kwargs)
print func.__name__, args, kwargs
return res
return wrapper
@benchmark
@logging
def reverse_string(string):
return str(reversed(string))
print reverse_string("Able was I ere I saw Elba")
这里还有。
5,补充:
decorator还可以是类,例如(捎带展示了descriptors)
class Property(object):
def __init__(self, fget):
self.fget = fget
def __get__(self, obj, type):
if obj is None:
return self
return self.fget(obj)
class MyClass(object):
@Property
def foo(self):
return "Foo!"
甚至任何callable的对象都可以?
yield in python
缘起至以前那篇python PerformanceTips,对通过yield实现的Generator产生了兴趣。
搜索了一下,stackoverflow上的一个回答介绍的很全面了,简单归纳一下要点:
1,首先明确python中for的语义:顺序迭代,以及iterable的含义。
2,Generators are iterators,但是不提供随机访问(__getitem__())。
3,当含有yield的函数被调用时,函数并没有执行,而是直接返回了一个generator object。
在这个object中猜测一定保存了函数的数据状态(locals and globals)和逻辑运行状态(类似EIP)。
然后每次next()调用时,generator根据当前的数据+逻辑状态生成当前值,同时保持状态为下一次迭代做准备。
4,只有Generators才能迭代一个无限长对象。
另外留几个无关的坑:decorator,descriptor,metaclass,以后要抽空分析一下。
py3源码[8]-多线程
1,python中的多线程是系统原生进程,但是受到GIL影响,性能有折损,but not too bad.
知乎上这个问题的扩展讨论:http://www.zhihu.com/question/21219976
2,thread(基础实现,build in,by c),threading(上层保证,std module,by python)
不同平台采用统一接口封装(python/thread_pthread.h,python/thread_nt.h)。
3,默认单进程启动,不采用GIL,避免无误开销。
4,2种调度方法:标准调度(约100条bytecode);阻塞调度(主动退出)。其中GIL是python和os多线程调度之间的桥梁。
5,threading同步/互斥的几个工具:
a,Lock,提供:get/release,互斥锁。
b,RLock,可重入版本Lock。
c,Condition,提供:wait/notify,事件锁。
d,Semaphore,保护n个相同资源,信号量。
e,Event,Condition的简单包装。
python PerformanceTips
原文:http://wiki.python.org/moin/PythonSpeed/PerformanceTips
给自己做的笔记。
1,方法论
Get it right.
Test it’s right.
Profile if slow.
Optimise.
Repeat from 2.
2,选择合适的数据结构
3,sort小技巧:按某一维排序
def sortby(somelist, n):
nlist = [(x[n], x) for x in somelist]
nlist.sort()
return [val for (key, val) in nlist]
def sortby_inplace(somelist, n):
somelist[:] = [(x[n], x) for x in somelist]
somelist.sort()
somelist[:] = [val for (key, val) in somelist]
return
//py2.4+
n = 1
import operator
nlist.sort(key=operator.itemgetter(n))
另外:sort()操作是稳定的。
From Python 2.3 sort is guaranteed to be stable.
(to be precise, it’s stable in CPython 2.3, and guaranteed to be stable in Python 2.4)
4,字符串拼接
多用join和位置参数替换
slist = [some_function(elt) for elt in somelist] s = "".join(slist) out = "<html>%s%s%s%s</html>" % (head, prologue, query, tail)
避免+拼接产生的多个临时对象。
5,循环
多使用内置循环函数(如map):
newlist = []
for word in oldlist:
newlist.append(word.upper())
newlist = [s.upper() for s in oldlist]
newlist = map(str.upper, oldlist)
map也许对应了一个较优化的字节码。
6,避免名字查找(个人不提倡)
upper = str.upper
newlist = []
append = newlist.append
for word in oldlist:
append(upper(word))
其实就是避免多次指针查询,而直接访问对应的locals()字典。
这是以牺牲可读性为代价的,个人觉得为了这一点点性能提升,完全没必要。
7,字典默认值
wdict = {}
get = wdict.get
for word in words:
wdict[word] = get(word, 0) + 1
8,用xrange替代range
避免内存短爆,xrange is a generator object。
generator object记忆了内部变量和控制流为下次调用使用,基础是yield操作符。
记住控制流挺不寻常,以后要了解一下其内部实现。
9,profile工具
直接使用标准库中的profiling modules即可。
业务代码其实打点日志就行了,用不上profile工具。
原文中还介绍了几个工具。
10,总结
一句话:严格遵守方法论,选对数据结构,记住join和xrange。
这基本就够用了~
py3源码[7]-内存管理与垃圾收集
这块暂时只记录了py2.5的实现方式,尚未对照py3是否有变动。
一,内存管理
1,总体层次:type级(freelist);object级(关键);底层(clib:malloc/free)。
2,object级详解:
a,申请小内存(<256byte)时,采用内存池方式分配。否则直接malloc。
b,内存池层次:arenas->arena->pool->block,见下图
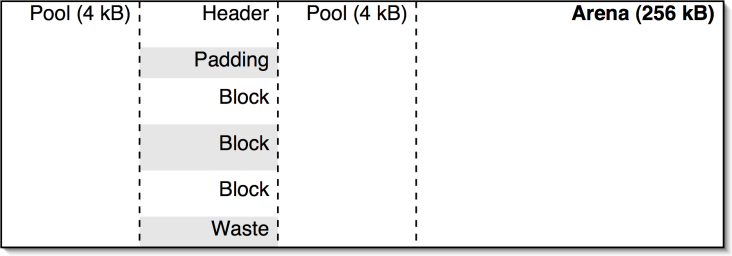
c,每个arena空间为定长256kb(具有一个arena_object头,图中未画出),存储着若干个pool;单个pool一般为页大小(4K),内联pool-header描述,存储某个定长(8Nbyte,max 256byte)的block;1个block为最小内存分配单位。
d,usedpools链表,用大小作为索引,串着同一个block大小的各个pool,作为分配总入口来加速分配。
e,一个arena空间都空闲的时候,是可以被收回的(>=py2.5,老版本存在内存泄漏)。
二,垃圾收集(GC)
1,引用计数+mark-sweep垃圾收集。为啥混合使用引用计数呢?这里有当时的设计思路。
2,引用计数:实现简单;具有实时性;对程序性能冲击小;垃圾收集:只针对容器对象(class,list,dict等),只处理循环引用。
3,垃圾收集三色标记,分代(3)收集,采用链表阈值触发收集,其中含有_del_方法的对象会导致内存泄漏。
并发与协程
闲读了一下《go语言编程》,简单摘录总结一下。
目前并发的几种实现模型:
1,多进程:稳定,隔离度佳,系统原生支持,但开销非常大,并发数一般几十级别。
2,多线程:中庸,依然是系统原生支持,开销一般。并发数一般几百级别。可以很好的解决大部分问题了。
3,基于回调的异步io:性能佳,但编码成本很高(不符合一般思维)。如:node.js。
4,协程:性能佳,用户态实现,采用了一个简单的抽象模型(消息传递,yield等)。并发数可以支持到百万级别,很适用于解决抽象上就是一个并发问题(如网游)。一般采用库方式实现,也有语言原生支持的如go。
协程的内部实现:
可以参考偶像Cox的libtask。核心基于2个系统调用:makecontext(),swapcontext()。
go的协程语言层面已经包装的很舒服了,在python方面比较成熟的就是stackless库了。看看features小节中的实例就很清晰了,接口和go很类似。
Python Extension
希望掌握一下这个技能。
自己写了一个示例,将ul_sign包装为一个python扩展
https://github.com/interma/misc/tree/master/py_extension
interma@debian:~/git/misc/py_extension/ul_sign$ python Python 2.7.3 (default, Jan 2 2013, 16:53:07) [GCC 4.7.2] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> import ul_sign >>> str="12334tret" >>> ul_sign.creat_sign_fs64(str,len(str)) (73391337, 957628440) interma@debian:~/git/misc/py_extension/ul_sign$ ./test 12334tret 12334tret:[73391337][957628440]
几个学习资料
官方手册:
http://docs.python.org/3/extending/extending.html
非常好的一个示例(from kdr2, :-)):
https://github.com/shuttler/nessDB/tree/v2.0/bindings/python
WSGI
“WSGI本身是一个用来确保你的web应用能够与webserver进行对话,更重要的是,确保web应用之间能够一起配合工作的协议或约定”
http://zh.wikipedia.org/zh-cn/WSGI
缘由:
以前,如何选择合适的Web应用程序框架成为困扰Python初学者的一个问题,这是因为,一般而言,Web应用框架的选择将限制可用的Web服务器的选择,反之亦然。那时的Python应用程序通常是为CGI,FastCGI,mod_python中的一个而设计,甚至是为特定Web服务器的自定义的API接口而设计的。
要点:
WSGI有两方:“服务器”或“网关”一方,以及“应用程序”或“应用框架”一方。服务方调用应用方,提供环境信息,以及一个回调函数(提供给应用程序用来将消息头传递给服务器方),并接收Web内容作为返回值。即把服务器功能以 WSGI 接口暴露出来。
而WSGI中间件同时实现了API的两方,因此可以在WSGI服务和WSGI应用之间起调解作用:从WSGI服务器的角度来说,中间件扮演应用程序,而从应用程序的角度来说,中间件扮演服务器。
server=>[midware1]=>[midware2]=>app(framewrok),举例:apache=>mod_wsgi=>[flup]=>Django
答疑:
http://eishn.blog.163.com/blog/static/652318201011082044410/
讨论:
http://wiki.woodpecker.org.cn/moin/WSGI
toolkit:
http://werkzeug.pocoo.org/docs/tutorial/#module-werkzeug
https://github.com/mitsuhiko/werkzeug/blob/master/examples/shortly/shortly.py
example很好的展示了MVTD(model/view/template/dispatch)

leave a comment